Evolving from Rule-based Classifier: Machine Learning Powered Auto Remediation in Netflix Data Platform
Original Blog Post: Evolving from Rule-based Classifier: Machine Learning Powered Auto Remediation in Netflix Data Platform
Authors: Binbing Hou, Stephanie Vezich Tamayo, Xiao Chen, Liang Tian, Troy Ristow, Haoyuan Wang, Snehal Chennuru, Pawan Dixit (from Netflix)
Published: 2023-08-31
My summary:
This blog post from Netflix, where they are using ML to supplement a rules-based approach to identifying errors as they occur in their data platforms and sometimes handle those errors automatically (“auto remediation”).
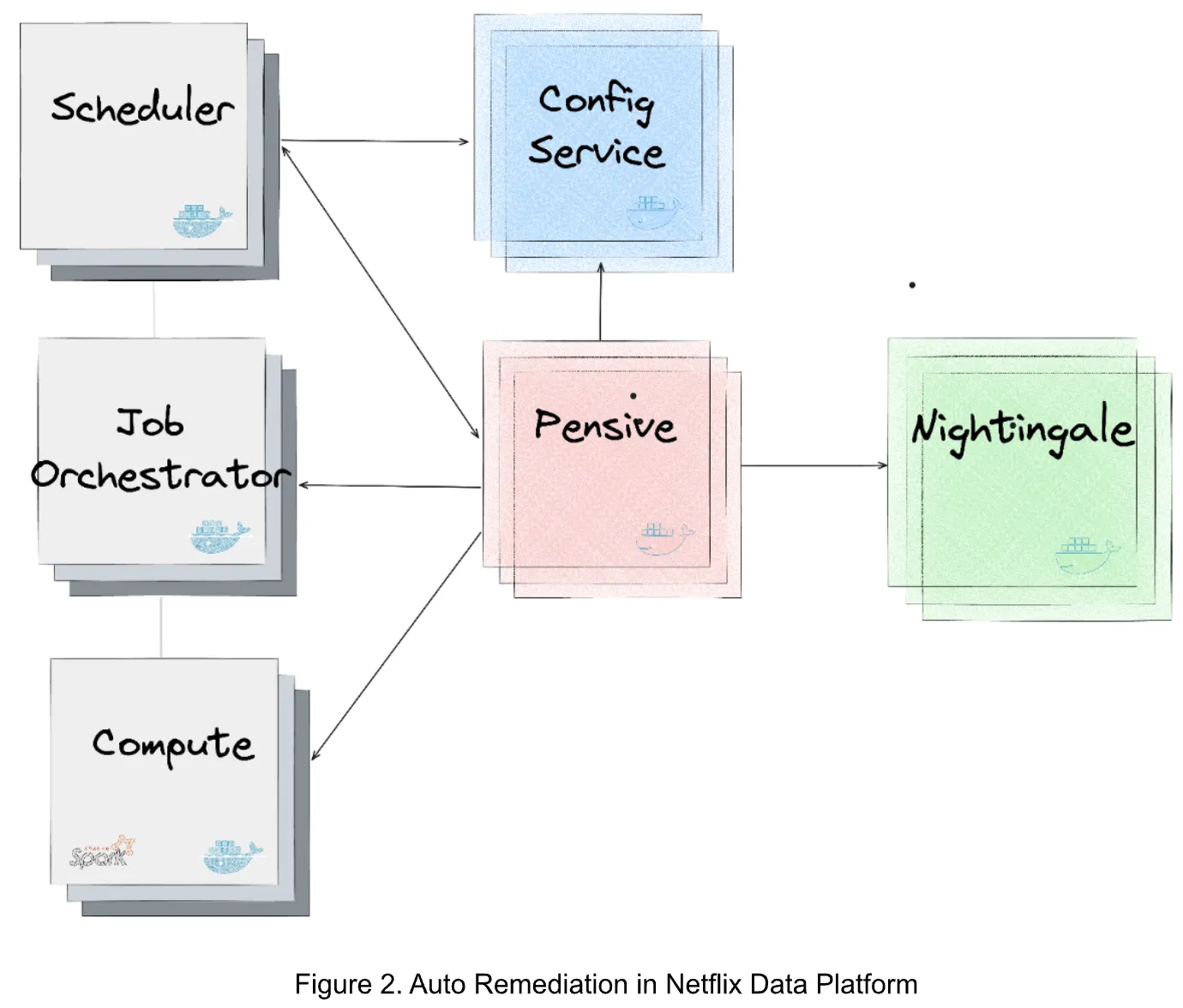
At Netflix, hundreds of thousands of workflows and millions of jobs are running per day across multiple layers of the big data platform.
With such a high level of activity in their data platform, even a small percentage of errors can increase costs and require considerable human effort to diagnosis and address errors.
Netflix started addressing this already with a rules-based engine they call Pensive, which classifies errors, helps determine whether to retry the job, and provides insights to human engineers who might need to remediate the job failure.
The rules-based engine however requires domain experts to create and test new rules as new errors and scenarios appear. Even with over 300 rules, half of all errors are still unclassified by this algorithm.
Therefore, they decided to supplement the rules-based algorithm with an ML approach, which allows them to:
leverage the merits of both: the rule-based classifier provides static, deterministic classification results per error class, which is based on the context of domain experts; the ML service provides performance- and cost-aware recommendations per job…
In practice, all errors go through the rules-based engine, then any memory configuration errors or unclassified errors are passed to the ML model.
With about 600 memory configuration errors occurring every month in their system, manually corrected these errors can be quite time-consuming, especially since it is not always straightforward what the correct configuration should be. Too little memory causes a “Out-of-Memory” error, and too much memory is not an efficient usage of cluster resources.
Therefore, they train a standard neural network (in other words, a feedforward multilayer perceptron - MLP), with two heads. Two heads means that the model has two outputs, so that they can simultaneously predict both the probability of failure and computation cost of retrying the job with a certain memory configuration.
Finally, they use a Bayesian optimization where the neural network is run multiple times with features based on the specific error and different options for the Spark run configuration, and the best combination of failure probability and computation cost is determined.
So far, this ML algorithm has automatically solved 56% of memory configuration errors and substantially reduced costs related to these errors.
Here is the link again to their blog post for more details: Evolving from Rule-based Classifier: Machine Learning Powered Auto Remediation in Netflix Data Platform